The moment a startup starts selling into larger customers, one document suddenly becomes more important than founders expected. It is not the pricing page, the MSA, or even the security questionnaire. It is the policy that explains what happens to data after the company collects it.
That moment usually arrives under pressure. A procurement team asks how long customer records sit in HubSpot, AWS, Slack, Google Drive, and backups. An investor diligence request asks whether deletion is automated or left to individual employees. Or litigation counsel sends a preservation notice, and the company discovers that ordinary cleanup rules may have already wiped messages that now matter.
A data retention policy template helps, but only if it is treated as a starting point. Startups in Washington have a particularly good reason to take this seriously. They often move fast across product analytics, health-adjacent features, support workflows, and AI-enabled tooling long before internal governance catches up. A generic template rarely reflects that operational reality.
Why Your Startup Needs More Than a Generic Template
A founder downloads a retention template after a customer security review asks for one. Two months later, counsel issues a litigation hold, support messages are still auto-deleting in one tool, stale exports are sitting in Google Drive, and no one can say which team owns deletion in backups. That is the point where a generic template stops being a shortcut and starts becoming evidence of weak governance.
A startup retention policy has to work in live systems, across real teams, under time pressure. Generic templates usually fail because they stay abstract. They say to keep records as long as required by law and delete data when no longer needed, but they do not tell a company how to apply those rules to product analytics, applicant data, customer content, finance records, security logs, vendor tools, test environments, and backups.

A template is not the policy
The policy is the operating rule set behind the document. It should identify data categories, the systems where they live, the retention period for each category, the legal or business reason for keeping them, the person who approves deletion, and the method for suspending deletion when a legal hold applies.
That distinction matters in customer diligence and in disputes. Knowledgeable buyers and opposing counsel are not interested in whether a PDF exists. They want to know whether the company can show a consistent lifecycle for applicant records, customer support tickets, audit logs, contract files, and regulated product data.
For startups, the gap usually appears in the same places. Slack becomes an unofficial record archive. A founder's laptop holds old CSV exports. Engineers keep snapshots in cloud storage long after the feature was sunset. Backups retain data long after the production system deleted it.
Practical rule: If a company cannot name the system of record and deletion owner for a dataset, it does not have a retention program. It has wishful thinking.
Startups face operational problems generic templates ignore
Early-stage companies change tools constantly. They add a new CRM, switch support platforms, create health-adjacent features, or expand into a new state before anyone updates internal controls. A template downloaded last year will not answer whether wellness data collected from Washington residents triggers different retention and deletion expectations than similar data collected elsewhere.
That is not a theoretical problem. Washington's My Health My Data Act can reach data categories and businesses that fall outside traditional healthcare regulation. A startup may end up applying different rules to the same workflow depending on what data it collects, where the user is located, and whether another law requires longer retention. Companies building in that area should review retention together with broader Washington data privacy and compliance requirements.
Legal holds create another failure point. Templates often mention preservation in one sentence and stop there. In practice, someone has to know how to pause deletion in email, chat, ticketing systems, cloud storage, device management tools, and backup processes without freezing the entire company indefinitely.
The business case is practical, not theoretical
Founders often treat retention work as paperwork until a customer, regulator, or court asks for proof. By then, the cost of improvising is high.
A customized policy helps in three concrete ways:
- It shortens diligence cycles. Enterprise customers want clear answers about where data lives, how long it stays there, and who can delete it.
- It cuts breach exposure. Data that has been deleted on schedule cannot be exposed later from forgotten systems.
- It improves defensibility. Consistent retention and documented legal holds are easier to explain than ad hoc cleanup that starts after a claim appears.
The operational side matters too. Startups with cloud-heavy stacks should treat retention as part of a broader compliance program for infrastructure, vendors, and access management. This guide for cloud hosting businesses is a useful companion for thinking through those dependencies.
A generic template can give a startup a format. It cannot decide which state law controls a dataset, how long backups should persist, when deletion must stop for a legal hold, or who owns execution in each system. Those are the decisions that make the policy real.
Anatomy of a Legally Sound Data Retention Policy
A legally sound retention policy should read like instructions for running the company under pressure. If a customer asks for deletion, a regulator asks why a record still exists, or a lawsuit requires preservation, the document should tell the team exactly what to do in the systems they use.
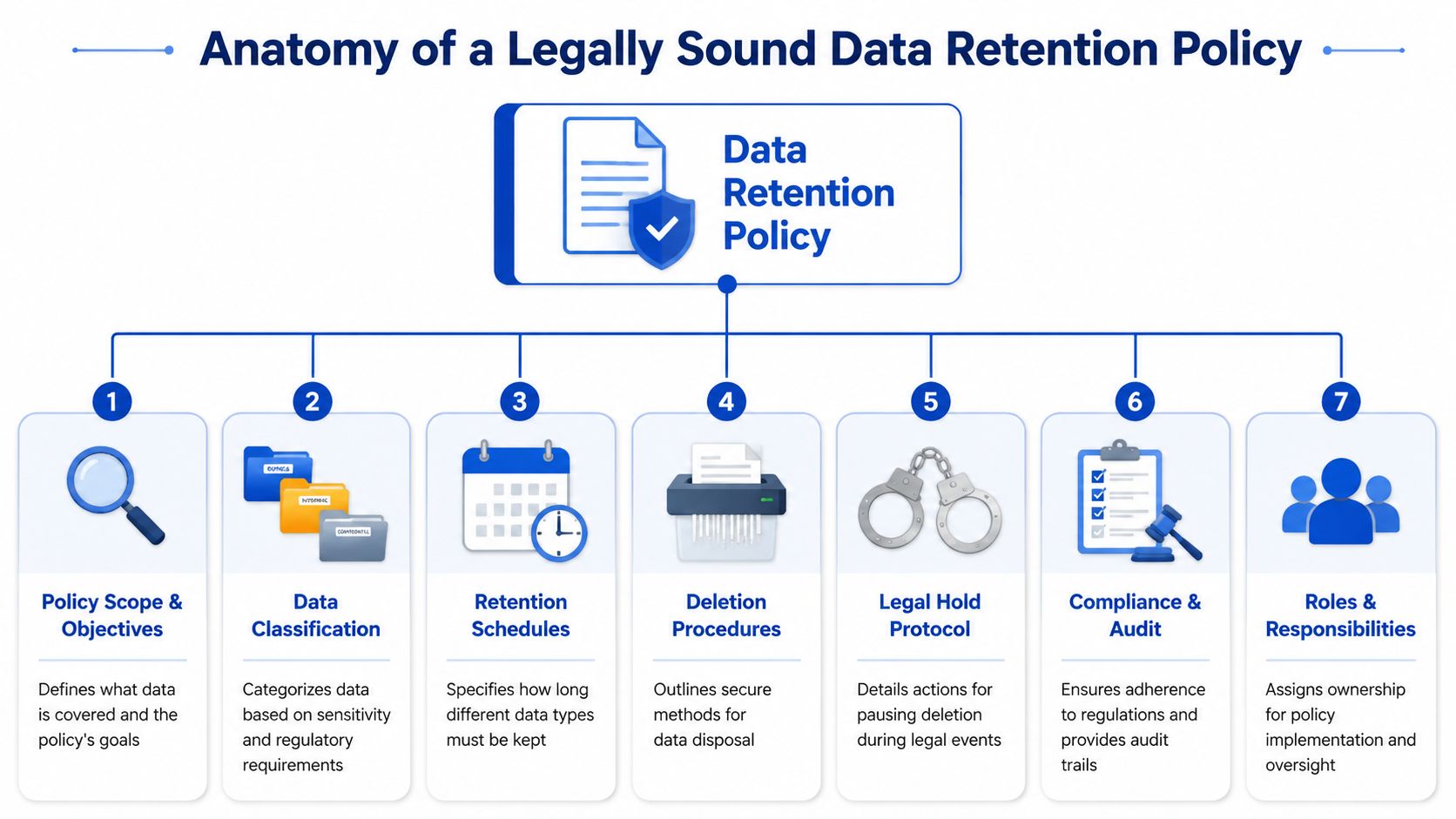
Scope and purpose
Start with reach. The policy should identify the entities, teams, systems, and data categories it covers, including shadow tools that tend to get missed in startups. If contractors work in Notion, sales runs through HubSpot, support uses Zendesk, engineers store artifacts in GitHub and cloud buckets, and HR records sit in an outsourced platform, the policy should say that plainly.
This section should also state why the company keeps data at all. That matters because retention is tied to purpose. If the business no longer needs a dataset for the reason it was collected, continued storage becomes harder to justify under privacy laws built around minimization and use limits, including Washington data minimization and purpose limitation requirements.
A vague scope causes predictable gaps. Teams assume the rule applies somewhere else, and old data stays put.
Roles and responsibilities
Retention programs fail when ownership is spread across committees and no one has authority to act. The policy should assign named roles with decision rights, escalation paths, and system-level duties.
A practical startup model often looks like this:
- Legal or privacy lead: approves retention periods, exceptions, and preservation decisions
- IT or engineering owner: configures deletion, archival, backup, and access controls
- Business system owner: confirms how data enters, moves through, and exits a tool
- HR and finance stakeholders: validate employment, tax, and accounting record obligations
- Security lead: confirms that destruction methods match the company's technical environment
That allocation matters most in cloud-heavy companies, where deletion settings, backup cycles, and vendor defaults often sit in different consoles. A founder who wants an operational reference can compare policy controls against this guide for cloud hosting businesses, which is useful for understanding how policy language maps to hosted systems and managed services.
Classification and retention schedule
The retention schedule is the part regulators, customers, and opposing counsel often care about first. It shows whether the company made deliberate decisions or copied a template without checking how the business works.
Good schedules do not assign one company-wide timeframe to everything. Customer contracts, product analytics, applicant records, security logs, tax documents, and health-related data raise different risks and are often subject to different legal rules. That problem is sharper for startups operating across states. A company may be able to keep one category of operational data for a business need, while a health-related dataset requires a shorter window, clearer disclosures, or tighter use restrictions under laws such as Washington's My Health My Data Act.
A usable schedule usually includes:
| Component | Why it matters |
|---|---|
| Data category | Separates customer records, HR files, logs, finance data, product telemetry, and intellectual property |
| System of record | Identifies the authoritative source and reduces fights over duplicate copies |
| Trigger event | Starts the clock at the right moment, such as account closure, contract end, or employee separation |
| Retention period | States how long the company keeps the record in active use or archive |
| Disposal method | Specifies deletion, anonymization, or transfer to archive |
| Owner | Assigns accountability for carrying out the rule |
The best schedules also explain the business and legal rationale for each timeline. Founders often prefer neat symmetry. Defensible retention rarely looks neat.
A visual summary can help internal teams absorb the structure before implementation:
Deletion, destruction, and exceptions
A policy is only as strong as its deletion language. “Delete securely” is not enough. The document should specify approved methods, required approvals, audit logging, treatment of archived exports, and what happens in backup environments where immediate deletion may not be technically possible.
That last issue is where startup policies usually break. The live app may purge data on schedule while backups, CSV exports, shared drives, and former vendor environments keep copies for months. If the policy does not address those repositories, the company has a paper rule rather than an operating rule.
The exception process deserves equal detail. The policy should say when routine disposal stops, who can issue a legal hold, how that hold is communicated, which systems must be preserved, and who confirms the hold was implemented. It should also acknowledge that conflicts happen. One law may support deletion, another may require preservation, and a pending claim may override both for a period of time. A sound policy does not pretend those conflicts do not exist. It assigns authority to resolve them and documents the decision.
How to Customize Your Data Retention Schedule
A founder approves a retention template on Friday. By Monday, the company learns customer messages live in Slack, support tickets, email, backups, laptops, and a contractor's exported CSV. The template looked clean. The actual retention schedule is not.
Customizing the schedule means turning a generic policy into operating rules your team can follow system by system. For startups, that work usually exposes two problems fast. No one has a full map of where data lives, and the same dataset may be subject to privacy deletion expectations, tax record retention, contract terms, and sector-specific rules at the same time.
Start with systems and workflows
Begin with the tools people use, not the categories a template assumes exist. For many startups, that includes Slack, Google Workspace or Microsoft 365, AWS, product databases, CRM systems, support platforms, HRIS tools, payroll software, source control, ticketing systems, shared drives, endpoint devices, and whatever sits in backups or archived exports.
Onna's guidance on data retention policy templates gets one point right. Inventory and classification come before retention periods. A usable schedule should identify the data category, system of record, trigger for the retention clock, deletion method, and internal owner. If legal or compliance is not reviewing those fields, the company is guessing.
Templates often fail here because they treat “customer data” as one bucket. Startups rarely store customer data in one place. Account data may sit in the production database, billing records in Stripe or a finance system, support history in Zendesk, and troubleshooting evidence in Slack threads or screen recordings.
Build categories that match real operations
The schedule should reflect how the business runs, not how a law textbook is organized. Early-stage companies do not need dozens of narrow categories on day one. They do need categories broad enough to administer and specific enough to justify.
A practical structure usually includes:
- Customer account data such as signup details, billing contacts, and account administration records
- Product and application logs such as access logs, security events, and diagnostics
- Support communications from ticketing tools, email, chat, and call recordings
- Marketing and sales records from CRM, web forms, ad platforms, and outreach tools
- Employee and applicant records from recruiting, HR, payroll, and benefits systems
- Finance and tax records from bookkeeping systems, payment processors, and banks
- Contracts and governance records such as NDAs, board materials, vendor agreements, and cap table support
- Research and development materials including source repositories, product specs, and design files
Slack deserves its own line item in many startups. Teams treat it as informal collaboration. Plaintiffs, regulators, and acquirers often do not. If your company has never set Slack retention intentionally, learn Slack archiving with Tutorial AI so operations and legal are working from the same picture of what can be preserved, archived, or removed.
Assign retention periods with a decision table
Retention periods should come from a repeatable analysis, not habit. I usually ask teams to document four questions for each category:
- Is there a law or regulation that sets a minimum retention period?
- Does a contract require the company to keep or delete the data within a defined window?
- What business purpose justifies keeping it after the minimum period ends?
- What risk increases if the company keeps it longer than necessary?
That last question matters more than founders expect. Data you keep can become evidence in litigation, scope in a security incident, or a violation of a deletion promise made in your privacy notice or enterprise contract.
Example data retention schedule for a tech startup
| Data Category | Example Records | Sample Retention Period | Governing Factor(s) |
|---|---|---|---|
| HIPAA-related policy and compliance records | Privacy procedures, required HIPAA documentation | At least 6 years from creation or when last in effect, depending on the document | HIPAA documentation retention requirements under 45 C.F.R. § 164.530(j)(2) |
| Security and compliance logs in regulated environments | Audit logs, access logs, monitoring evidence | At least 3 years where applicable | Security log retention may be driven by the applicable framework or contract, such as PCI DSS requirement 10 |
| Grant administration records | NSF-related submission and reporting records | At least 3 years after submission of the final expenditure report, for many awards | Federal grant retention rules described in 2 C.F.R. § 200.334 |
| Customer support messages | Tickets, support emails, chat transcripts | Defined by product needs, dispute risk, and privacy commitments | Business purpose, customer promises, and minimization analysis |
| Marketing leads | Demo requests, newsletter signups, CRM lead notes | Defined by consent, campaign purpose, and deletion standards | Privacy law requirements, documented purpose, and internal policy |
| Employee records | Personnel files, leave requests, performance documentation | Defined by employment, tax, payroll, and dispute requirements | State and federal employment obligations plus claims defense needs |
| Product analytics tied to identifiable users | User event histories, feature usage linked to accounts | Defined by purpose and product need | Documented purpose limitation analysis |
| Slack and internal collaboration data | Channel messages, shared files, project chats | Defined by legal exposure, operational value, and preservation capability | Internal governance decision, tool settings, and hold-readiness |
Washington startups need to be especially careful with data that can reveal health conditions, treatment interests, symptoms, reproductive or gender-affirming care, or location tied to care. A generic schedule that groups this material into ordinary product analytics can create real exposure under Washington law. This overview of data minimization and purpose limitation laws in Washington State is a useful starting point for identifying where standard SaaS retention logic may fail.
Record the reason, not just the period
Every line item should have a short rationale. One sentence is enough if it answers the key question: why this period, for this data, in this system?
Good rationales sound like this: “Keep payroll tax records for the applicable tax and employment law period.” Or: “Delete marketing leads after the campaign purpose expires unless the contact becomes an active sales opportunity.” Weak rationales sound like this: “Industry standard,” or “template default.”
That discipline pays off later. During diligence, an audit, or a regulator inquiry, the company can show that each retention period was chosen deliberately, tied to a legal rule, a documented business need, or a defined risk decision. That is what separates a policy on paper from a schedule a startup can defend.
Handling Legal Holds and Conflicting Regulations
The most dangerous sentence in many retention policies is also the shortest: “Data will be deleted automatically according to schedule.” That is fine until deletion must stop.
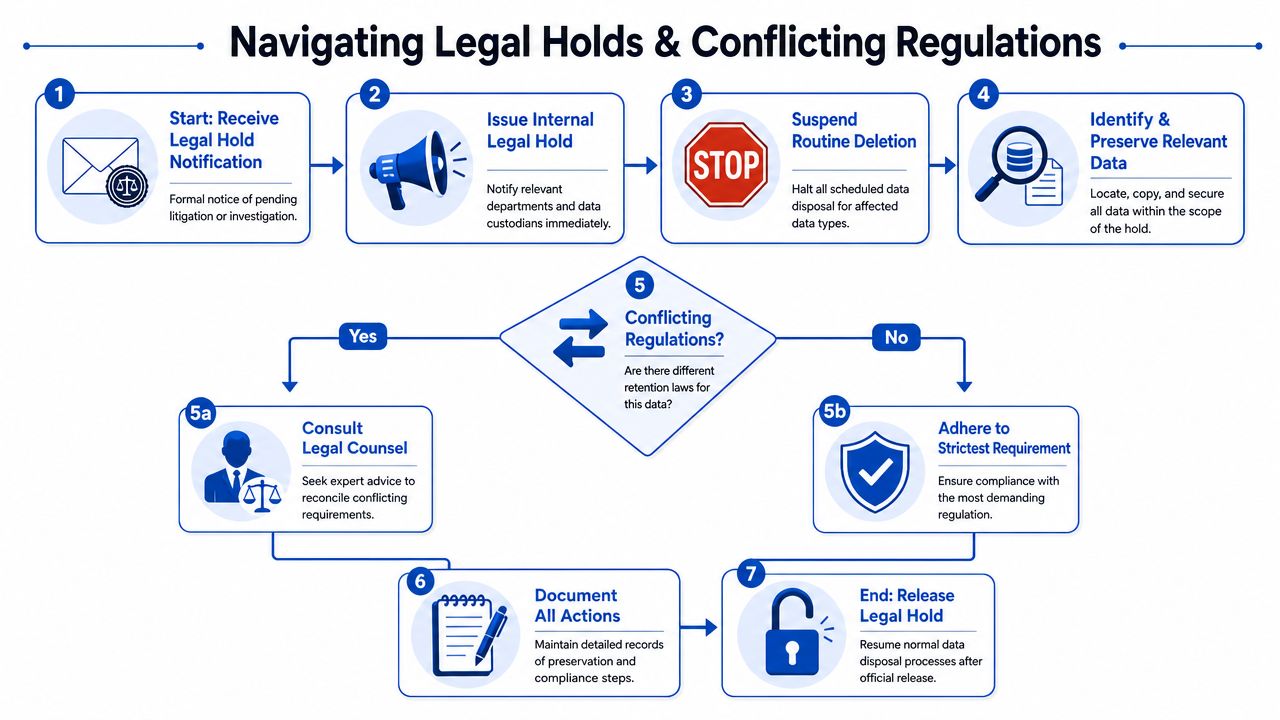
Legal holds cannot be an afterthought
A strong policy must say that records cannot be destroyed if they are relevant to ongoing or anticipated litigation or investigations, and it should define the workflow for pausing routine deletion. That gap is highlighted in the Council of Nonprofits sample retention policy language, which is more operationally useful on legal holds than many startup-oriented templates.
A legal hold procedure should answer five concrete questions:
- Who can issue the hold
- Which custodians and systems are affected
- How IT or engineering suspends deletion
- How preserved data is tracked
- Who has authority to release the hold
Without those details, the company does not have a hold process. It has a hope that people remember to stop deleting things.
One dataset can be governed by multiple rules
Startups often assume each record maps cleanly to one law. In reality, one dataset can trigger privacy duties, tax obligations, employment obligations, contractual commitments, and litigation preservation requirements at the same time.
Consider a Washington startup building a consumer wellness product. Some records may look like ordinary product analytics to the engineering team, customer support material to operations, and sensitive health-related data to a privacy lawyer. Add a dispute with a former employee or a regulator inquiry, and the lifecycle becomes more complicated immediately.
A practical decision framework looks like this:
| Question | Action |
|---|---|
| Is there an active or reasonably anticipated legal matter? | Pause ordinary deletion for in-scope data |
| Is there a mandatory retention requirement? | Keep the data for that mandatory period |
| Is another rule pushing toward shorter retention or deletion? | Document the conflict and analyze whether the longer mandatory rule controls |
| Is retention based only on convenience? | Reassess whether that business justification is actually defensible |
| Has the conflict been documented and approved? | Record the decision, owner, and review date |
Keep three buckets in the schedule: mandatory retention, permissible retention, and business-justified retention. That structure makes conflicts visible before they become mistakes.
For consumer-facing businesses, the conflict analysis often overlaps with deletion rights and state privacy obligations. Teams dealing with those requests should coordinate retention rules with a broader CCPA compliance checklist, especially where the company serves users across multiple states.
The safest pattern is not “always keep the longest period no matter what.” It is “identify the mandatory rule, identify the deletion pressure, document why one governs, and review the decision again when the law or product changes.”
Your Implementation and Training Checklist
A polished policy that nobody operationalizes is dead paper. Implementation is where the startup decides whether the retention schedule will live in a binder or in the systems employees use.
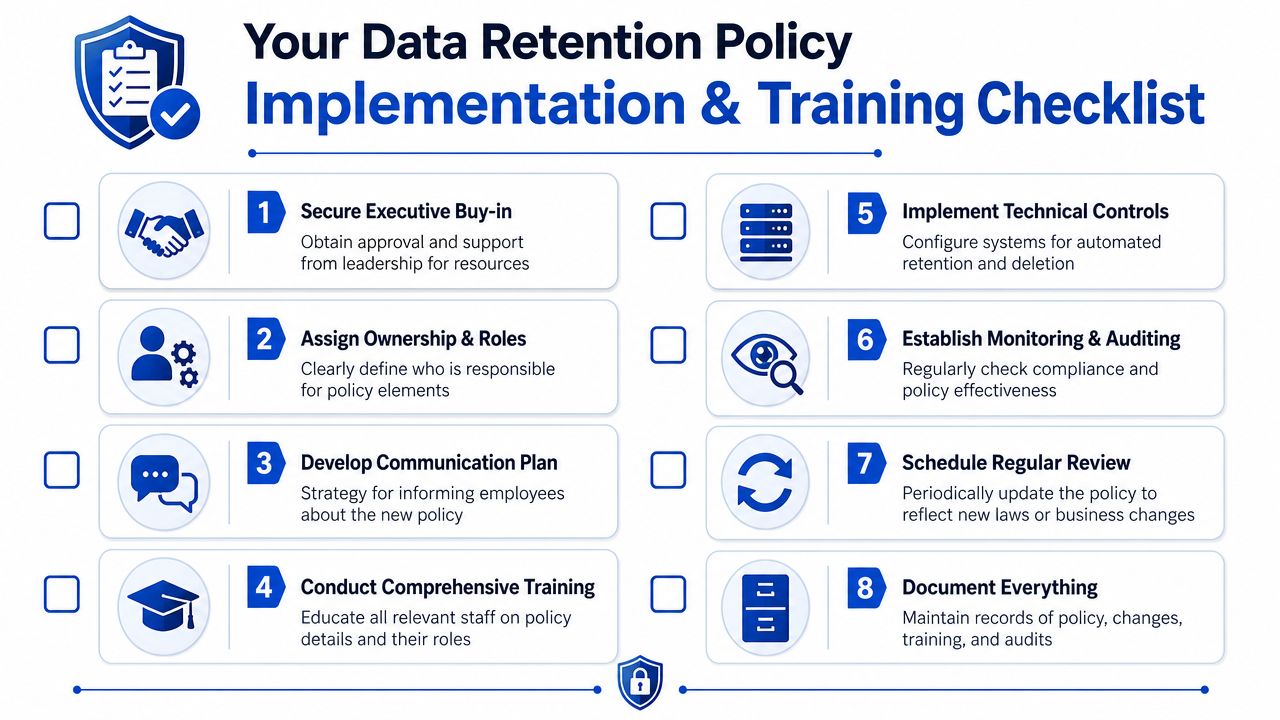
Put the policy into the stack
The company should convert the schedule into settings, workflows, and approvals inside its actual tools. That may mean Slack retention settings, Google Workspace or Microsoft 365 rules, CRM lifecycle fields, ticketing archive rules, cloud storage lifecycle policies, and documented backup handling.
Training has to be role-specific. Engineers need to understand logs, backups, and preservation workflows. HR needs to know which employment records are official. Sales and support teams need to stop creating shadow archives in personal folders or unmanaged exports.
A rollout checklist that works
- Get executive approval: Leadership sign-off gives the policy authority and helps resolve conflicts between convenience and compliance.
- Assign named owners: Each system and record class should have an accountable owner, not a generic shared department label.
- Translate the schedule into system settings: Manual deletion should be the exception, not the primary control.
- Train by role: A one-size-fits-all privacy training rarely covers retention duties well enough.
- Create a hold escalation path: Employees should know who to contact the same day a preservation issue appears.
- Document exceptions: If a tool cannot yet support the desired lifecycle, write down the gap and the interim safeguard.
- Review access rights: Retention and deletion authority should not be broader than necessary.
- Track changes and reviews: Version control matters when auditors, customers, or counsel ask how the policy evolved.
The implementation phase should also tie into the company’s broader incident readiness. Retention, deletion, and preservation decisions become especially sensitive after a security event, when teams may need logs, notices, and response records quickly. This practical checklist on data breach response planning for Seattle businesses is a useful companion for that part of the governance program.
FileCloud’s discussion of retention best practices makes an important point here. One of the hardest problems is creating a single policy that handles overlapping and conflicting retention rules, which is why a good program separates mandatory and permissible retention and requires periodic review.
Auditing Your Policy to Ensure Ongoing Compliance
The fastest way for a retention program to become unreliable is to treat it as finished. Startups change products, tools, business models, customers, and markets quickly. A static schedule cannot keep pace with that.
What an audit should test
An audit does not need to be theatrical. It needs to be honest.
The company should review whether the written schedule still matches actual systems and behavior. That includes checking whether deletion rules run as expected, whether archived data remains accessible when needed, whether new tools were adopted outside the policy, and whether legal holds can suspend routine disposal in practice.
A useful audit usually asks:
- Did any new data categories appear? Product launches and AI features often generate them, sometimes subtly.
- Did any team adopt a new tool? This is common with recruiting, support, analytics, and collaboration software.
- Did the business enter a new jurisdiction or market? New geographies can change retention assumptions.
- Did regulators or customers ask new questions? Their requests often reveal policy gaps before internal teams notice them.
- Did any exception remain open too long? Temporary workarounds tend to become permanent unless tracked.
A mature company is not the one with the longest policy. It is the one that can show the policy matches real operations.
Review timing and evidence
The audit should produce artifacts, not just meeting notes. Keep the current schedule, prior versions, approvals, exception logs, training records, and evidence that technical settings were reviewed. That record matters in customer diligence and disputes because it shows the company is governing data intentionally rather than improvising after the fact.
For Washington startups, this ongoing review is especially important where products touch health, biometrics, location, employment data, or high-volume user analytics. A retention rule that looked proportionate when the company had one product line may become a poor fit after expansion, acquisition, or a new enterprise customer segment.
A data retention policy template is useful at the beginning. Ongoing compliance depends on the company’s willingness to revisit assumptions, update the schedule, and close the gap between written policy and live systems.
By Design Law Firm & Legal Consultancy, PLLC helps Washington startups and growing businesses build practical data governance programs that stand up in diligence, disputes, and day-to-day operations. For companies that need customized guidance on retention schedules, privacy compliance, breach readiness, contracts, or technology risk, By Design Law Firm & Legal Consultancy, PLLC offers clear, business-focused legal counsel designed for real-world execution. Call our law office today at (206) 593-1519.


