A startup doesn't need a cyber incident response plan because regulators expect one. It needs one because tested plans are tied to lower losses. IBM-linked analysis cited by BitSight reports that organizations with a tested incident response plan reduce breach costs by an average of $2.66 million compared with organizations that don't test their plan, according to BitSight's incident response planning guide.
For founders, that changes the conversation. A cyber incident response plan isn't an IT binder for auditors. It's a business continuity system that tells the company who makes decisions, who preserves evidence, who speaks to customers, who contacts counsel, and how the company moves without creating additional legal exposure.
Why a Cyber Incident Response Plan Is Non-Negotiable
A workable cyber incident response plan gives a company a decision system for the first hours after discovery, when facts are incomplete, pressure is high, and legal exposure can expand with every uncoordinated step. For a startup founder, the immediate questions are rarely technical alone. Is this a security event or a reportable incident? Which systems can be taken offline without stopping revenue-critical operations? Who approves containment if it affects customers, payroll, or product availability? What evidence has to be preserved before anyone wipes a device or restores a backup?
The familiar NIST lifecycle helps because it forces order into that chaos. The current structure still centers on preparation, detection and analysis, containment and recovery, and post-incident review. Founders do not need to memorize framework language. They do need a plan that connects those phases to named people, core systems, outside vendors, insurance requirements, and legal deadlines.
For startups and SMBs, that legal layer is where many plans fail.
A response plan has to do more than assign IT tasks. It should tell the company when counsel is pulled in, when privilege considerations matter, when the cyber insurer requires notice, and when customer contracts or state breach laws may start the clock. If the company has users, employees, or vendors in Washington, for example, the plan should account for the notice and timing issues outlined in this guide to Washington data breach notification requirements.
What the plan does under pressure
In smaller companies, the common breakdown is delay caused by uncertainty. The security lead is waiting on leadership approval. Leadership assumes the MSP is handling forensics. Someone from customer success wants to reassure an enterprise client before the facts are settled. Meanwhile, logs are overwritten, the insurer has not been notified, and a casual Slack message creates a record that will look bad later.
A useful plan reduces that risk by assigning decisions before the incident starts:
- Operational control: It states who can isolate endpoints, disable accounts, cut off third-party access, or take a cloud environment out of service.
- Legal control: It defines when legal review begins, what evidence must be preserved, and which laws, contracts, or regulator expectations may apply.
- Communication control: It sets approval paths for employee notices, customer updates, board communications, and any external statement.
- Recovery control: It ranks systems by business impact so the company restores what keeps the business running, not what generates the most internal noise.
Practical rule: If authority has to be debated during an incident, the plan is too vague to protect the business.
What works and what fails
The plans that hold up in a real incident are short, role-based, and built for time pressure. They include current contact details, escalation triggers, outside forensic and insurance information, decision logs, and clear criteria for containment and restoration. They also reflect the company as it exists now, not as it looked a year ago when the document was first drafted.
Weak plans usually fail for predictable reasons. They read like policy manuals. They copy framework language, define basic security terms, and spend too little time on approvals, evidence handling, notification triggers, or customer commitments in contracts. I have seen companies lose valuable time because the document looked polished but gave no answer to a simple question such as who can authorize shutting down a production system tied to a service-level agreement.
Founders should treat the incident response plan the same way they treat a financing checklist or a major customer agreement. It protects enterprise value, supports business continuity, and helps the company respond in a way that is technically sound and legally defensible. That matters to investors, customers, insurers, and regulators for the same reason. A company that can respond with discipline usually contains both operational damage and avoidable legal risk.
Laying the Groundwork with Roles and Legal Triggers
Across all sectors, only 42.7% of companies have cybersecurity incident response plans and test them annually or more, and 45% of companies have an incident response plan in place, according to NetDiligence's discussion of incident response plan adoption. For startups and SMBs, that gap creates both risk and opportunity. The risk is obvious. The opportunity is that a company with a disciplined response structure often looks more mature than peers of the same size.
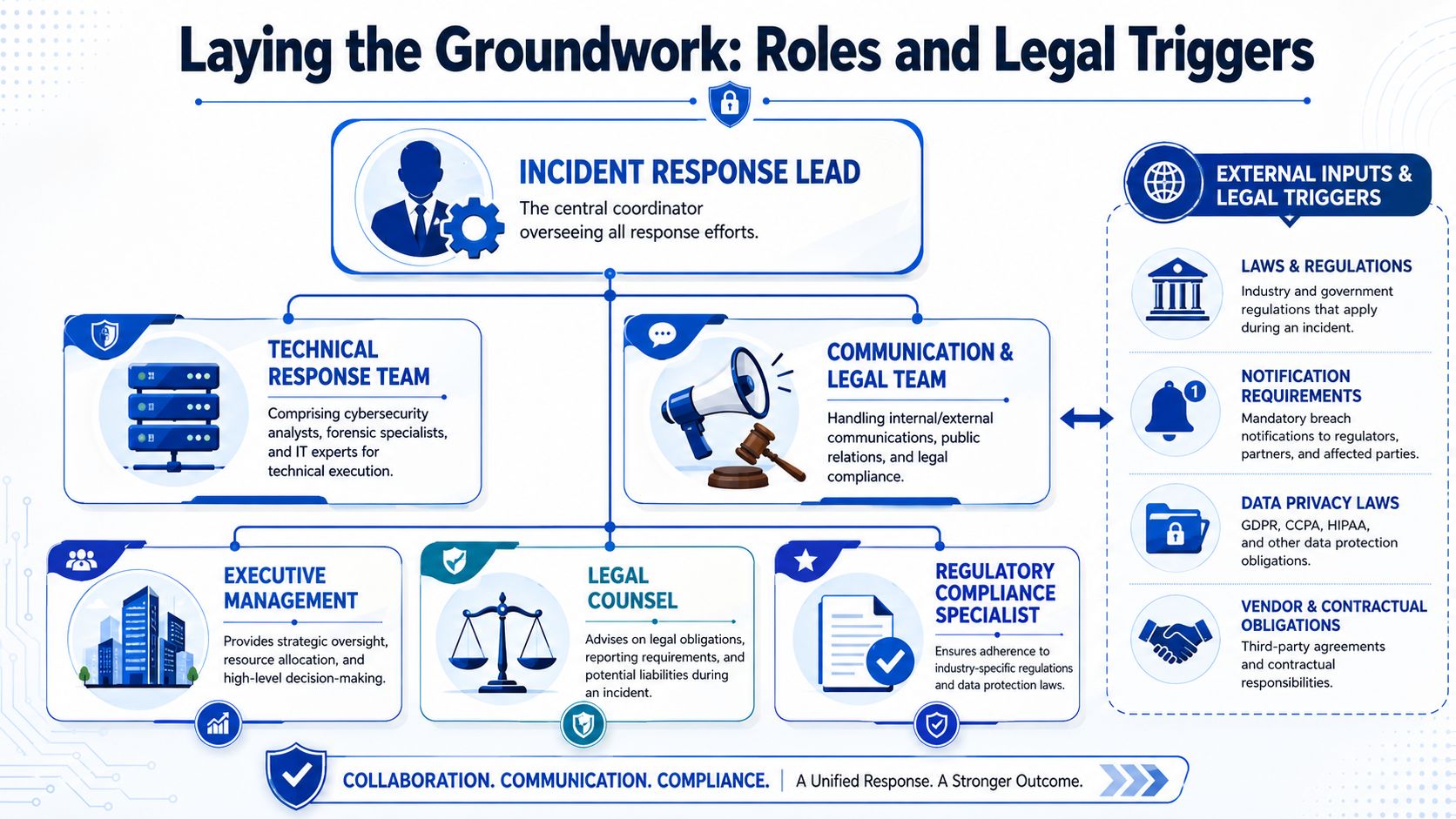
Build the team before drafting the document
A plan written before roles are assigned usually becomes fiction. The names and functions have to come first.
Most startups and SMBs need these core roles:
- Incident Response Lead: This person coordinates the response, owns the timeline, and makes sure decisions are recorded. In a small company, this may be the CTO, head of security, or a senior operations leader.
- Technical Lead: This person directs triage, validates indicators, manages containment, and works with internal IT, an MSP, or outside forensics.
- Legal Counsel: This person assesses notification duties, privilege strategy, evidence preservation, contractual obligations, and regulator-facing decisions.
- Communications Lead: This person controls outbound messaging to employees, customers, partners, and, when needed, the public.
- Executive Decision-Maker: Usually the CEO or another senior executive who can approve business trade-offs, including downtime, vendor spend, and customer-facing decisions.
In regulated or data-heavy businesses, two more functions are often necessary:
- Privacy or Compliance Owner: Useful when the incident may involve personal data, health data, employee information, or sector-specific rules.
- Vendor Coordinator: Critical when the company relies on cloud platforms, payroll vendors, SaaS tools, or an outsourced security provider.
The company doesn't need a large team. It needs a team with authority, alternates, and current contact information.
Map legal triggers, not just technical triggers
Most plans do a decent job saying when to escalate a malware alert. Many do a poor job saying when to escalate to legal.
That's a problem because legal triggers often arrive before full technical certainty. A founder should identify, in advance, the events that require legal review, such as suspected unauthorized access to personal data, compromise involving customer environments, ransomware with possible exfiltration, employee device loss involving company data, or incidents that may trigger contractual notice clauses.
A practical legal trigger list should cover:
- Regulatory exposure: Whether the company handles personal, consumer, employee, or health-related data in ways that may create notice duties.
- Contractual notice duties: Enterprise customer contracts, data processing agreements, and vendor terms often require prompt notice even when the law doesn't.
- Insurance notice obligations: Cyber policies may require early notice and approved vendors.
- Preservation needs: If litigation, law enforcement, or insurer review is possible, preservation starts immediately.
- Board and investor governance: Some incidents require rapid escalation to governance stakeholders even before the company knows the full scope.
Washington companies should also build state-specific notice analysis into the plan. For a practical starting point, the company should maintain a legal trigger checklist tied to Washington data breach notification requirements.
What founders often miss
Founders often assume the incident response plan starts when the security team confirms a breach. That's too late. The legal version of “start” is often earlier. It begins when facts suggest the company may have an obligation to preserve evidence, notify a counterparty, or avoid making inaccurate statements.
The team should know who can say “this now goes through legal review” and what happens next. Without that gate, technical teams may overwrite logs, customer success may reassure clients too early, and executives may promise timelines no one can support.
Constructing Your Core Response Plan Document
A response plan works only if the team can use it under pressure. The document should read like an operating manual, not a policy memo. I usually advise startups to organize it around the NIST phases, but with named decision-makers, approval thresholds, and legal hold points built into each phase so the company can protect evidence, meet notice duties, and keep the business running.
Early in drafting, it helps to review how other practitioners frame effective data breach response. External examples will not fit your company out of the box. They are useful for spotting gaps, especially where an internal draft says who investigates but not who approves customer communications, insurer notice, or vendor escalation.
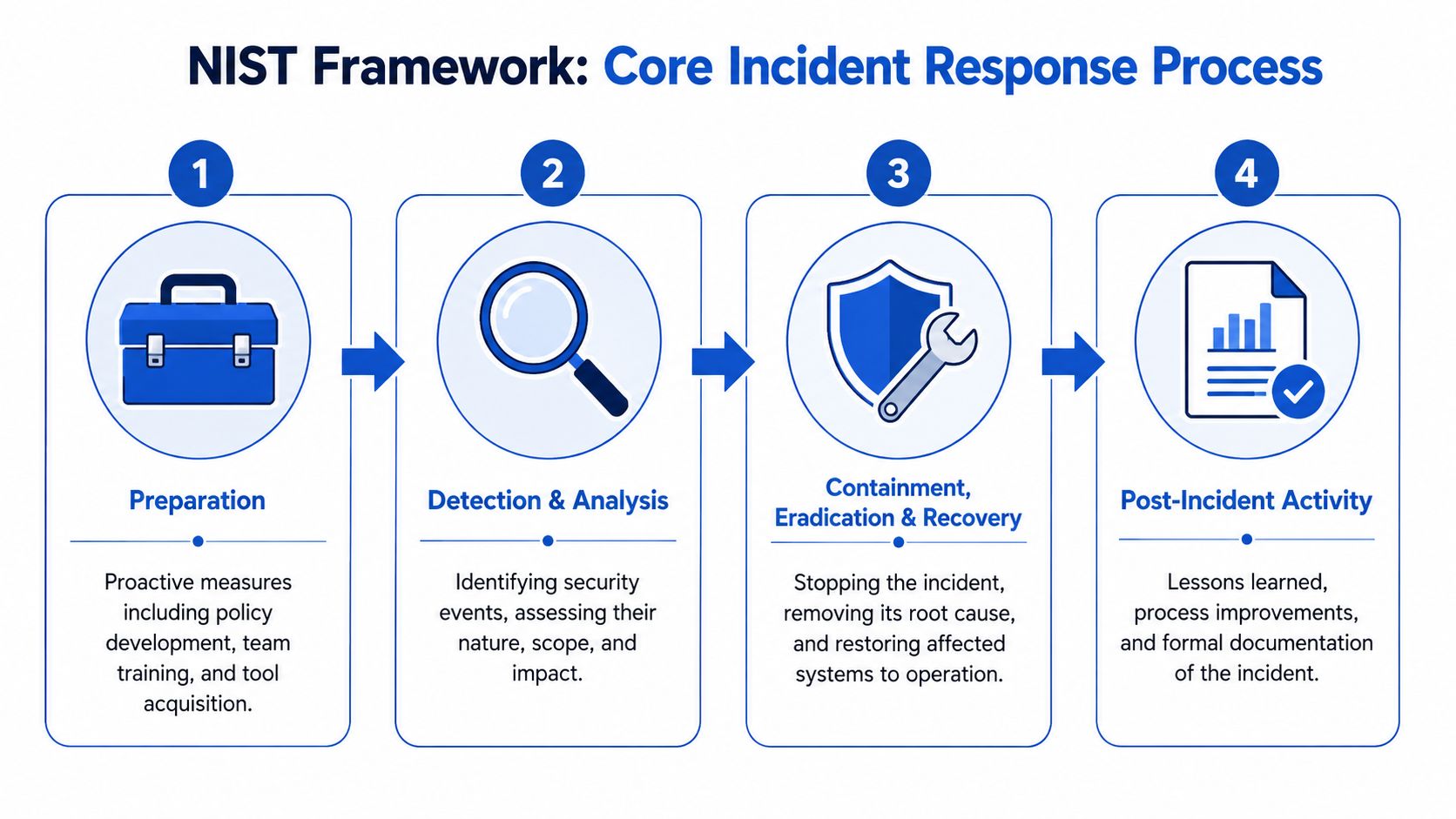
What to write in the preparation section
The preparation section should identify the people, systems, tools, and outside parties the company will rely on before an incident occurs. For most startups, that means documenting:
- Team roster and alternates
- After-hours contact details
- Key vendors and contracts
- Asset priorities
- Backup and restoration ownership
- Cyber insurance carrier and panel counsel details
- Law enforcement decision criteria
- Document retention and evidence handling instructions
Communication control belongs here too. During an incident, teams often shift to text threads, personal email, or side-channel messaging. That creates avoidable discovery, confidentiality, and recordkeeping problems. The plan should state which channels are approved for incident coordination, who can authorize a switch to an out-of-band channel, and which decisions must be recorded before the team makes customer, regulator, or insurer-facing statements.
For companies that handle customer data, the plan also needs a contract map. Security addenda, enterprise MSAs, data processing terms, and audit clauses often impose deadlines and cooperation duties that matter before the forensic facts are complete. A short matrix tied to key agreements, paired with a data processing agreement template, helps the company identify who must be notified, what assistance may be owed, and whether a vendor must approve subcontractor or forensic access first.
Here's a useful training asset for teams that need a quick overview of the lifecycle before drafting detailed procedures:
Make detection and analysis the decision gate
According to CrowdStrike's incident response steps overview, mature plans include a risk classification matrix, update cadence, communication workflow, evidence-preservation rules, and tabletop/full-simulation testing. The hardest step is often detection and analysis, because that is where the company decides whether an event is routine noise, a security incident, or a business problem with legal consequences.
The plan should not stop at “investigate alerts.” It should define how the team classifies events and who has authority to change that classification.
A practical matrix should ask:
| Classification factor | What the team should assess |
|---|---|
| Business impact | Which revenue, operational, or customer-facing functions are affected |
| Data sensitivity | Whether the incident touches personal, confidential, or regulated data |
| Scope | Whether a single device, account, application, or broader environment is involved |
| Recoverability | Whether the company can restore safely from backups or alternate systems |
| External exposure | Whether customers, vendors, regulators, or law enforcement may need to be involved |
The convergence of legal and business continuity planning is evident. A contained malware alert on a low-value endpoint may rank below suspected access to an executive mailbox tied to payment approvals or customer records. The technical severity may be lower, but the fraud risk, privilege issues, and notice exposure are often higher.
Decision test: If two incidents arrive at once, the plan should tell the team which one gets executive attention first and why.
Write containment, recovery, and lessons learned as operating instructions
Containment and recovery sections should answer hard questions in plain language. Can engineering disable a user account globally without manager approval? Who can take a production system offline if customer uptime commitments are in play? When must the team collect logs, preserve cloud snapshots, or image a device before remediation starts? Which outside parties, such as the insurer, a major customer, or managed security provider, must be contacted before restoration?
These trade-offs are where weak plans fail. Fast cleanup can destroy evidence. Perfect preservation can slow restoration and increase downtime. The document should tell the team how to balance those interests by incident type, who breaks ties, and when legal review is mandatory because litigation, breach notice, or contractual dispute risk is on the table.
The post-incident section should require a written review with a set format. It should capture the timeline, decision log, preserved evidence, communications sent, vendor performance, customer impact, and control changes assigned to owners with deadlines. If the review stays at “what happened,” the company gets a file. If it records what must change in contracts, access controls, logging, and approval paths, the company gets a better response plan the next time.
From Plan to Action with Practical Playbooks
The master plan gives authority and structure. Playbooks give speed. They're short checklists for recurring incident types so the team doesn't have to search a long document while systems are failing or inboxes are being hijacked.
For most startups and SMBs, three playbooks belong at the front of the stack: ransomware, business email compromise, and lost or stolen device.
Three examples that teams can actually use
A ransomware playbook should start with immediate isolation and preservation. A business email compromise playbook should focus on account control, message tracing, and payment fraud risk. A lost-device playbook should assume the device may contain cached data, active sessions, or multifactor tokens.
Here's a compact model:
| Incident Type | Initial Containment Action | First Communication Step |
|---|---|---|
| Ransomware | Isolate affected endpoints, servers, or storage from the network and pause automated sync where appropriate | Notify the incident lead, legal, and executive decision-maker that operational disruption and possible data access issues are under review |
| Business email compromise | Disable or restrict the affected account, revoke active sessions, and secure related admin access | Alert finance, leadership, and internal stakeholders that suspicious email activity may affect payment instructions or external communications |
| Lost or stolen employee device | Revoke device access, remote-lock or wipe if available, and invalidate high-risk sessions | Notify the incident lead and legal so the company can assess what company or personal data may have been exposed |
First five actions for common scenarios
For ransomware, the opening sequence should usually include:
- Isolate first: Remove affected systems from normal connectivity.
- Preserve evidence: Capture logs, screenshots, ransom notes, and system details before broad remediation.
- Check spread risk: Review whether shared drives, identity systems, or cloud storage are involved.
- Engage counsel and insurer: This helps manage privilege, vendor approvals, and notification sequencing.
- Control internal messaging: Employees need one source of truth, especially if systems are unstable.
If the team wants a technical companion resource focused on prevention and operational response, Titanium Computing's ransomware guide is a useful reference point.
For business email compromise, the first moves are different. The company should secure the mailbox, review forwarding rules, identify spoofed payment requests, and alert anyone who may act on fraudulent instructions. This is also where vendor risk comes into view. If the compromised account had access to customer portals, procurement systems, or vendor records, the company's vendor security assessment process should help determine downstream exposure and required outreach.
A good playbook fits on one or two pages. If responders need to scroll through policy prose, the playbook is too long.
For lost or stolen devices, the mistake is treating the event as a help-desk matter. It may be one. It may also be a data incident, depending on local storage, privileged access, and synced applications. The playbook should force a quick review of what the device could reach, not just whether the hardware can be replaced.
Testing and Refining Your Incident Response Plan
A plan fails under pressure for predictable reasons. Phone numbers are stale. Authority lines are fuzzy. The insurer expects one notice path, while the MSP follows another. Testing exposes those gaps before an incident turns them into missed deadlines, bad evidence handling, or a notice mistake that creates legal exposure.
That is why testing matters beyond security operations. A well-run exercise shows whether the company can meet its regulatory duties, preserve privilege, follow customer contract terms, and keep the business running while key people are making time-sensitive decisions.
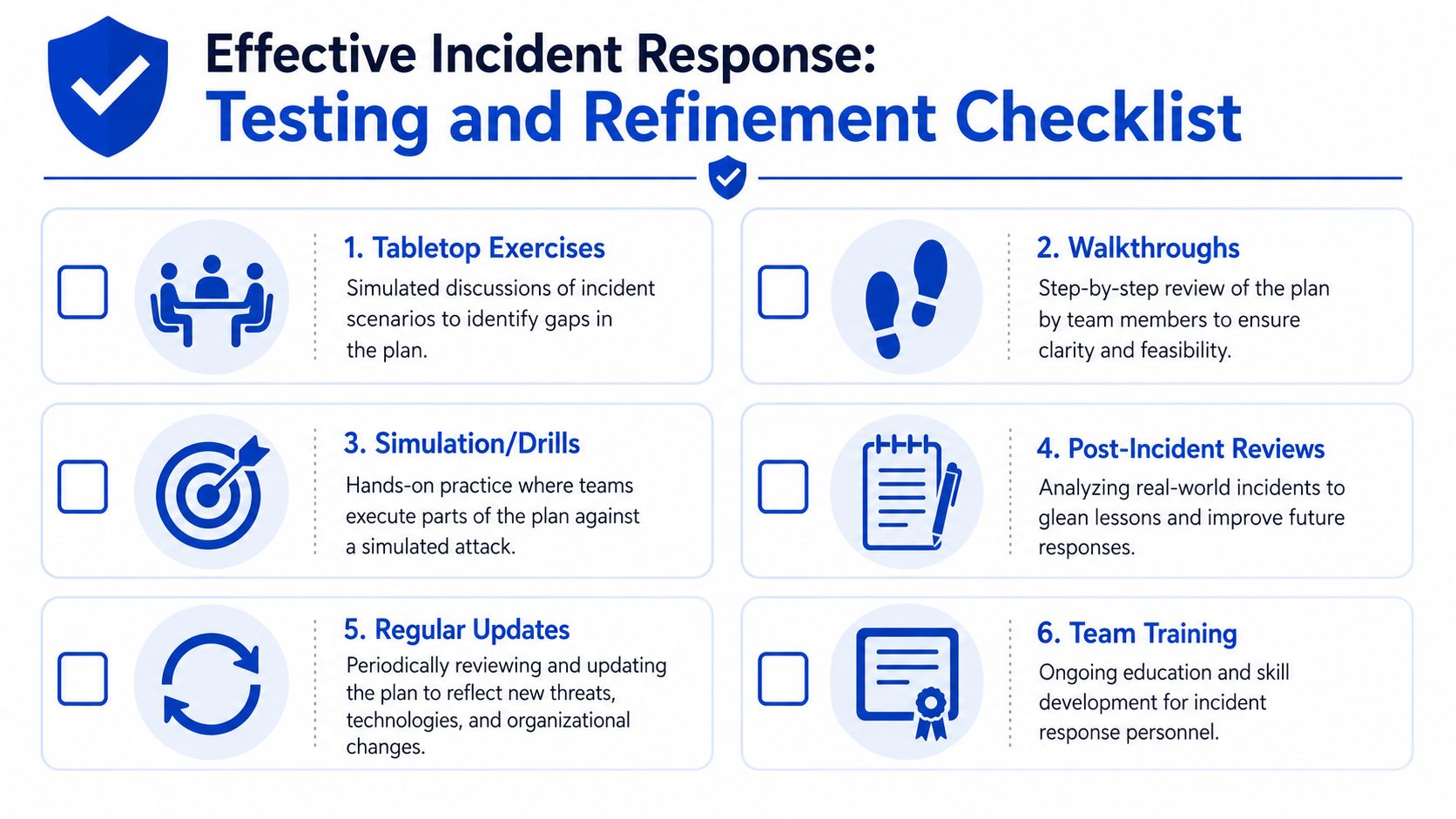
Start with exercises the business will run
Early-stage companies and SMBs usually get more value from disciplined tabletop sessions than from expensive simulations. The goal is to surface confusion, not to stage a dramatic attack.
A practical testing sequence looks like this:
- Tabletop exercise: Run a realistic scenario with leadership, IT, legal, communications, and anyone who owns customer or vendor relationships.
- Workflow walkthrough: Confirm that contact trees, escalation paths, approvals, and after-hours procedures work as written.
- Functional drill: Test a narrow action, such as disabling accounts, collecting logs, preserving evidence, or restoring a critical system.
- Post-incident review: Use real incidents, including minor ones, to revise the plan, playbooks, and supporting contracts.
Every exercise should end with assigned fixes, owners, and dates. “Training completed” is not a useful result.
Test the plan against contracts, coverage, and real dependencies
Technical scenarios are only part of the job. Many response failures come from legal and commercial assumptions that were never checked. The company expects the cloud provider to retain logs. The insurer requires approved vendors. A customer contract sets a short notification window. The MSP believes it can contain systems without waiting for internal approval. Those conflicts should be found in an exercise, not during a live event.
A productive review should compare the plan against:
| Review area | Key question |
|---|---|
| Cyber insurance | Does the policy require prompt notice, panel vendors, or specific evidence-handling steps? |
| MSP and security vendors | Who investigates, who approves containment, and who preserves evidence? |
| Cloud and SaaS providers | What logs, support, and restoration help are available under the contract? |
| Customer contracts | What notice, cooperation, and security commitments apply during an incident? |
For a practical framework, use this data breach response planning checklist for Seattle businesses to compare the written plan against actual obligations.
A useful test puts pressure on decisions, approvals, and legal triggers, not just on technical tools.
Revise the plan when the business changes
Incident response plans age fast. A new product launch, a new HR platform, expansion into another state, or a large enterprise customer with tighter contract language can all change what the company must do in the first few hours of an incident.
That is where outside support becomes part of operational readiness. Many companies rely on a mix of outside forensics, an MSP, insurer-appointed vendors, and counsel such as By Design Law Firm & Legal Consultancy, PLLC to align response steps with privacy obligations, contract terms, and evidence preservation requirements. The point is simple. Identify those resources in advance, define when they are called, and test whether the handoff works.
Integrating Your IRP into the Business Culture
A cyber incident response plan works best when employees recognize that it's part of normal business operations. Security incidents rarely stay inside the security team. Sales may receive customer questions first. Finance may spot payment fraud first. HR may hear about a stolen laptop first. Engineering may see the first abnormal log entry.
That means culture matters. A resilient company trains people to escalate early, document facts carefully, and avoid freelancing communications. Employees don't need deep forensic knowledge. They do need to know what to report, where to report it, and why preserving evidence matters.
Signs the plan is part of the company, not just a file
A company is integrating its plan well when these behaviors are visible:
- Leaders use the same playbooks the team uses: Executives don't bypass the process because they're under pressure.
- Contracts and policies align with reality: Customer promises, vendor obligations, and internal procedures don't contradict one another.
- Training is short and recurring: Teams get scenario-based refreshers rather than a single annual lecture.
- Post-incident learning changes operations: The company updates access controls, vendor management, and communications practices based on what happened.
A founder should view the incident response plan as evidence of management maturity. It helps protect customer trust, supports better board oversight, and reduces the chance that a stressful technical event becomes a larger legal and reputational problem because the company responded inconsistently.
The strongest plans don't eliminate incidents. They help the business respond in a way that preserves options, protects relationships, and keeps a bad day from becoming a company-defining failure.
By Design Law Firm & Legal Consultancy, PLLC helps startups and established businesses build practical legal infrastructure around cybersecurity, data privacy, contracts, and incident response. Companies that need help aligning a cyber incident response plan with regulatory duties, customer agreements, vendor relationships, and breach response workflows can learn more at By Design Law Firm & Legal Consultancy, PLLC.


