A founder is about to sign a meaningful annual contract for a cloud platform that stores customer data, powers logins, or runs a core API. The demo looked polished. The sales team promised reliability. The order form, though, says very little about what happens when the platform goes down, slows to a crawl, or mishandles sensitive information.
That gap is where a service level agreement template matters. For startups, an SLA isn't a technical appendix that procurement files away. It's the part of the deal that turns marketing language into measurable obligations, creates a paper trail before something breaks, and gives the company a path to enforce performance without improvising in the middle of an outage.
Most startup teams still use outdated SLA language. They ask for uptime, maybe support response times, and stop there. That approach misses key exposures in a modern stack: shared cloud dependencies, API performance, data handling, security escalation, and AI-enabled services whose outputs can affect customers even when the underlying system is technically “available.”
Why Your Startup Needs More Than a Handshake
A weak vendor contract usually fails in predictable ways. It promises “commercially reasonable efforts.” It avoids specifics on reporting. It leaves exceptions broad enough to swallow the rule. Then the first serious incident arrives during a product launch, a customer migration, or a fundraising diligence process, and the startup discovers it bought a promise with no measurement and no remedy.
That's why a practical SLA should be treated as a risk allocation document. It answers basic business questions in concrete terms. What service is covered. What level of performance is required. How performance is measured. Who reviews it. What happens if the vendor misses.
Vague promises create expensive disputes
Historically, SLA templates became more operational as service relationships matured. Public-sector templates show the shift clearly. Rutgers' Administrative Support Services describes an SLA as identifying baseline and optional services, and a Veterans Affairs template requires “monthly reports to document the level of” service with centrally accessible data, which shows how performance became something parties verify rather than assume in practice, as reflected in the Rutgers SLA materials.
A founder doesn't need a public-sector contract style. A founder does need the discipline behind it.
Practical rule: If a vendor can't describe the service, the exclusions, and the reporting cadence in writing, the startup is accepting operational risk on trust alone.
The problem is rarely bad intent. The problem is misalignment. Sales wants speed. Engineering assumes flexibility. Legal wants optionality. The startup ends up signing standard terms that fit the vendor's revenue model, not the customer's exposure.
The SLA is often the real operating contract
For a startup, the master agreement may handle payment, ownership, confidentiality, and liability caps. The SLA is where service risk lives day to day. That's especially true when the vendor touches customer-facing systems, production data, authentication, analytics, or AI workflows.
A useful service level agreement template should force a conversation about issues like these:
- Critical dependency mapping: Which features are mission-critical, and which are nice to have.
- Reporting discipline: Whether the provider must produce recurring service reports or merely respond when asked.
- Exception control: Whether maintenance windows, third-party failures, and customer-caused issues are narrowly defined.
- Commercial advantage: Whether the startup gets credits, termination rights, or escalation access when service degrades.
Startups that are tightening their legal infrastructure often review SLAs alongside other core agreements such as those discussed in essential contracts for business owners. That's the right instinct. A core vendor without a real SLA can create the same level of business risk as an unfinished customer contract or a missing IP assignment.
Anatomy of a Modern SLA Core Components Explained
A modern service level agreement template should read like an operating manual with legal force. It shouldn't bury the critical obligations in abstract language. Every core clause should answer a practical question someone on the business, product, security, or legal team will eventually ask under pressure.
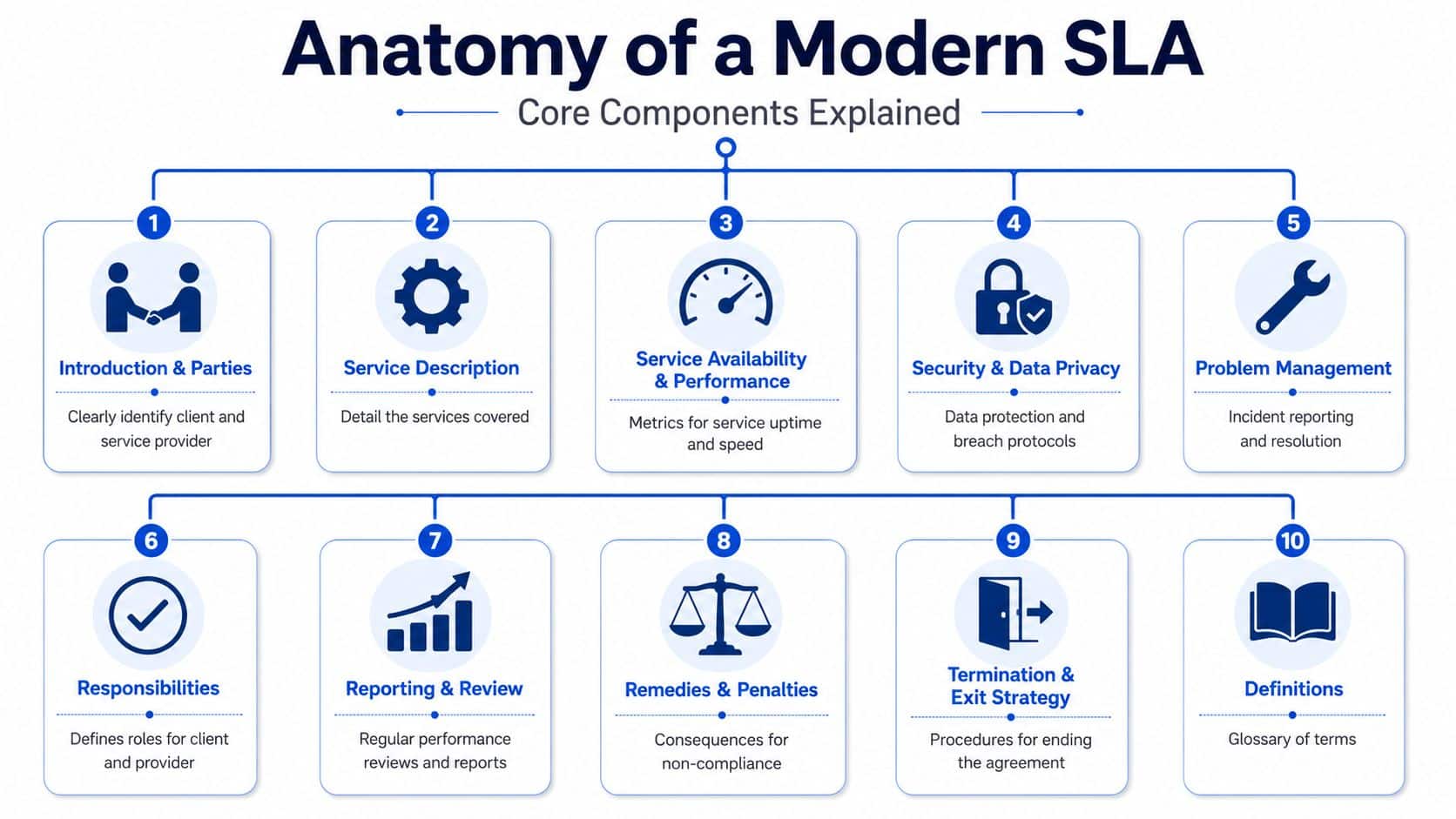
Start with identity and scope
First, identify the parties, the effective date, and the services covered. That sounds basic, but many disputes begin because the agreement never cleanly defines which affiliate, reseller, or subcontracted entity is responsible for performance.
Then define the service description. That clause should state what the provider is delivering, what systems or modules are included, whether there are baseline and optional services, and what dependencies sit outside the provider's commitment.
Questions worth pinning down early:
- Named services: Which applications, APIs, environments, or support functions are covered.
- Included support: Whether onboarding, migration assistance, and incident support are part of the base fee.
- Excluded work: Which change requests, integrations, or advisory tasks fall outside the SLA.
- Customer dependencies: What the startup must maintain for the SLA to apply.
Performance and support terms do the heavy lifting
The next layer covers service availability, performance, support, and incident handling. Within this layer, startups should resist generic wording. “High availability” means very little without a measurement method, maintenance carveout, and incident classification process.
A strong draft usually includes:
- Availability standards tied to a defined service boundary.
- Support responsiveness based on severity, not a single queue time.
- Problem management rules for incident intake, triage, escalation, and closure.
- Reporting obligations that require recurring service summaries.
- Review cycles so the SLA is maintained instead of forgotten.
An SLA that only says “provider will use reasonable efforts” is a courtesy statement, not a control mechanism.
Governance clauses separate mature templates from generic ones
The best templates also include responsibilities, remedies, termination, and definitions. These clauses are where many downloadable forms fall short. They state service goals but omit who owns what, when data must be shared, or how disputes move up the chain.
A practical checklist for the back half of the document looks like this:
| Component | Why it matters |
|---|---|
| Responsibilities | Prevents finger-pointing between customer and provider |
| Reporting and review | Creates a recurring compliance record |
| Remedies and penalties | Gives missed service levels a business consequence |
| Termination and exit | Protects continuity if the relationship fails |
| Definitions | Eliminates ambiguity in key terms |
Founders that need support reviewing these clauses often work with counsel focused on contract and transactional law, particularly when the vendor's paper is heavily provider-favorable.
Defining and Measuring Key Performance Indicators
An SLA without measurable performance indicators isn't much of an SLA. It's a statement of intent. The discipline comes from converting business expectations into metrics that can be tracked, audited, and challenged if necessary.
The baseline legal point is straightforward. ISO/IEC 20000 requires service level targets in SLAs, and a commonly used uptime benchmark is 99.99%, which equals about 52 minutes and 35.7 seconds of downtime per year, as explained in Splunk's discussion of service level agreements and SLA templates. That example matters because it shows how quickly a clean-looking percentage becomes a very small downtime budget in real operations.
Choose metrics that match the business risk
Startups often overfocus on uptime and underdefine everything else. Availability matters, but it doesn't capture a service that is technically online while returning errors, slowing down customer workflows, or failing on critical endpoints.
The better approach is to map KPIs to actual operational pain points.
| KPI | What It Measures | Example Target | Measurement Method |
|---|---|---|---|
| Availability | Whether the covered service is up and reachable during the measurement period | 99.99% uptime | Automated monitoring against defined service endpoints, with scheduled maintenance and agreed exceptions documented |
| Response time | How quickly the provider acknowledges a support issue | Defined by severity level | Ticketing system timestamps and incident logs |
| Resolution time | How quickly the provider restores service or provides a workaround | Defined by severity level | Incident records, closure notes, and post-incident review |
| Performance | Whether the system responds within acceptable technical limits | Defined for critical workflows or APIs | Application monitoring, synthetic tests, and shared dashboards |
| Reporting compliance | Whether the provider delivers agreed performance reports | Monthly or other agreed cadence | Delivery of recurring reports and shared access to service data |
Define the measurement method before arguing about the number
A startup should press hard on four drafting details.
- Measurement window: Is performance measured monthly, quarterly, or on a rolling basis?
- Service boundary: Is the metric tied to the application, API gateway, dashboard, or another layer?
- Excluded events: Which maintenance windows or customer-caused issues don’t count?
- Source of truth: Which logs, dashboards, or reports govern if the parties disagree?
Without those details, two reasonable people can read the same metric and reach different conclusions.
The number isn’t the whole promise. The monitoring method is part of the promise too.
Keep the KPI set lean enough to manage
Too many startup SLAs read like a wishlist. They contain every metric anyone could want and no realistic governance around any of them. A better structure uses a short list of high-value KPIs tied to customer impact, then aligns monitoring and reporting around those few items.
For most tech startups, the sensible starting set is:
- Availability for core services
- Support response time for priority incidents
- Resolution or restoration time for severe outages
- Performance thresholds for customer-critical workflows
- Reporting cadence so accountability doesn’t depend on memory
If the vendor can’t measure a metric reliably, that’s a drafting warning. Either the metric needs refinement or the startup is relying on a level of operational maturity the provider doesn’t have.
Customizing Your SLA for Tech and Data-Driven Business
A generic service level agreement template usually assumes a conventional SaaS relationship. User logs in. Software is available. Support answers tickets. That’s no longer enough for startups that depend on APIs, embedded models, analytics pipelines, managed data environments, or third-party cloud infrastructure sitting underneath the vendor’s product.
The deeper issue is governance. An SLA for a modern tech company often has to manage service ownership, exceptions, data dependencies, and changing product scope over time. Guidance on internal SLAs makes this point well: effective SLA structures should be flexible, future-proof, and reviewed quarterly against telemetry, especially in enterprise and shared-service settings where accountability and exceptions drive the core value of the document, as noted in Info-Tech’s discussion of internal service level agreement templates.
Generic uptime language misses modern failure modes
A startup using an AI-enabled vendor may have no complaint about “availability” while still facing a serious business problem. The model may return unusable outputs. The retrieval layer may fail on certain document types. The vendor may change a third-party model without notice, which changes quality, latency, or compliance posture.
A startup relying on API-heavy infrastructure faces a different issue. The dashboard may stay online while key endpoints degrade. Customer workflows fail. Revenue and reputation take the hit. The vendor then points to overall service availability and says the SLA was met.
That’s why a modern template should extend beyond uptime. It should address the service as the customer consumes it.
Clauses that deserve customization
For tech and data-driven businesses, these additions usually matter more than founders expect:
- API-specific commitments: Define which endpoints are covered, how performance is measured, and what counts as a failed transaction.
- Data processing integrity: Require clear handling rules for ingestion, transformation, storage, export, and deletion.
- Change management controls: Require notice for material changes to architecture, dependencies, or processing methods.
- AI output governance: Clarify whether the provider makes commitments around output consistency, content filtering, escalation for harmful results, and rollback when a model update causes issues.
- Third-party dependency language: State how outages or failures in underlying cloud or model providers are treated.
- Exception handling: Narrow the carveouts so the vendor can’t classify every meaningful disruption as excluded.
A startup doesn’t buy “software” in the abstract. It buys a chain of dependencies. The SLA should reflect that chain.
Review the SLA as a living document
Many templates are drafted once and ignored. That fails quickly in a startup environment where product scope changes, integrations expand, and data flows become more sensitive.
Quarterly review is often the right governance rhythm when the service is operationally important. The review should compare the written SLA against telemetry, support patterns, change history, and actual customer impact. If the vendor’s role has expanded, the SLA should expand too.
For teams negotiating cloud, data, and platform terms, resources on digital assets, data rights, and online platform contracts can help frame where service performance and data governance intersect.
Remedies Liabilities and Escalation Procedures
An SLA becomes useful when missed commitments trigger a response that the provider takes seriously. That response doesn’t have to be punitive, but it does have to be real. Otherwise the metrics are decorative.
The most effective templates treat monitoring, reporting, remedies, and escalation as connected controls. IT Toolkit’s guidance on SLA templates makes that point directly by emphasizing that strong SLAs include enforceable reporting, remedies, dispute resolution, and escalation procedures so underperformance can be addressed early instead of maturing into a larger contract fight, as described in its overview of SLA templates and examples.
Service credits are useful but limited
Service credits are the most common SLA remedy. They have value, but founders shouldn’t overestimate them. A small credit rarely compensates for customer churn, reputational damage, or internal fire drills.
That doesn’t mean credits are worthless. It means they should be drafted carefully.
- Tie credits to real failures: Trigger them for defined misses, not vague dissatisfaction.
- Avoid sole remedy traps: If possible, don’t let credits be the exclusive remedy for every breach.
- Require automatic application or simple claims: A remedy that requires a complicated claim process often goes unused.
- Escalate repeat failures: Recurrent misses should lead to stronger rights, not the same small credit every time.
Escalation should be operational before it becomes legal
A good escalation ladder reduces heat and improves documentation. It tells both sides who must speak, when, and with what decision-making authority.
A practical sequence often looks like this:
- Initial notice through the ticketing or service channel.
- Operational review between delivery managers or technical leads.
- Management escalation if the issue repeats or remains unresolved.
- Executive review for chronic failures, roadmap conflicts, or material business impact.
- Formal dispute process only after the operational path fails.
This structure protects the startup in two ways. It creates pressure inside the vendor organization, and it builds a record if termination or litigation later becomes necessary.
Termination and indemnity need attention
If the provider repeatedly misses critical service levels, the startup should have a credible exit. Termination rights tied to chronic nonperformance are often more valuable than credits because they restore strategic control.
Indemnity deserves careful review too, especially where service failure overlaps with third-party claims, security issues, or data misuse. Founders dealing with liability allocation often benefit from a close look at the importance of indemnity clauses in Washington State contracts, particularly when a vendor’s form agreement pushes nearly all downstream risk back to the customer.
Integrating Security Privacy and Breach Response
A vendor can hit its uptime target and still create your worst operational day of the year. For a startup handling customer data, API traffic, internal models, or regulated records, the harder risk is often a security failure that triggers customer notices, regulator questions, forensic costs, and lost trust.
That is why a modern SLA cannot stop at availability metrics. It should connect directly to the contract’s security, privacy, and incident-response terms so the provider’s duties are clear before anything goes wrong. Generic promises like “commercially reasonable security” rarely help much at 2 a.m. during an active incident.

Security commitments should be operational, not aspirational
Startups should press for obligations an engineering lead, security lead, and counsel can all test against actual facts. The clause should identify what data the vendor receives, how it is classified, where it may be stored, and whether it can be used for service improvement, model training, analytics, or subcontractor processing. That last point matters more now than it did in older SLA templates, especially where AI features and shared infrastructure create reuse risk that the customer never intended to accept.
Useful security language often covers:
- Data handling rules: defined categories of customer data, approved purposes, storage locations, and retention limits
- Access controls: role-based access, approval requirements, and prompt deprovisioning when personnel change roles or leave
- Encryption obligations: minimum standards for data in transit and at rest
- Audit and assessment rights: security reports, certification summaries, penetration test information where appropriate, and remediation tracking
- Backup and recovery alignment: recovery commitments that match the startup’s own continuity requirements
Short clauses can still be strong. They just need measurable obligations, clear owners, and enough detail to support enforcement.
Breach notification language should remove ambiguity
The breach clause should answer the questions that come up in the first few hours. What counts as a reportable incident. How fast notice must be sent. What facts the provider must share at the start. Whether logs must be preserved. Who speaks to customers, regulators, and the press.
A workable breach-response provision usually includes:
- Notice after discovery of any security incident affecting covered systems or data, within a defined time period
- Initial incident details sufficient for triage, even if the investigation is incomplete
- Status updates during containment, investigation, and recovery
- Cooperation duties for forensic review, mitigation, and legally required notices
- Preservation of evidence including logs, access records, and relevant system snapshots
- Corrective action obligations with documented remediation steps and follow-up reporting
Polished language is not enough here. If the clause does not tell the incident team what happens on day one, it will fail under pressure.
Privacy and security need to match the service model
A payroll provider, cloud host, customer support platform, and AI vendor should not all get the same SLA language. Their risk profiles differ, and the contract should reflect that. A startup sharing product telemetry or anonymized usage data may accept one set of controls. A startup sending customer files, prompt data, health information, payment details, or internal source code needs a tighter structure around access, subprocessors, retention, and incident handling.
Many older SLA templates often fall short. They were built around uptime and response times, not around data lineage, vendor access to sensitive prompts, or secondary use of customer information inside AI-enabled services. Founders should make the provider state, in plain terms, whether customer data will train models, feed benchmarking, support product development, or move across regions. If the answer is yes, the SLA and main agreement should allocate that risk directly instead of burying it in a policy link that can change later.
SLA Negotiation and Implementation Checklist
A founder signs a vendor SLA to close procurement and get the product team live. Three months later, an outage hits during a customer launch, support tickets pile up, and the vendor points to a broad maintenance exclusion and a reporting process no one inside the startup owns. That is usually not a drafting failure alone. It is a negotiation and implementation failure.

The best time to negotiate an SLA is before signature, while the provider still wants the business and before your switching costs increase. Large vendors may refuse to rewrite every liability clause, especially on standard paper. They will often make practical concessions on service descriptions, measurement methods, reporting cadence, support workflows, named exclusions, and escalation contacts. Start there. A high uptime commitment has limited value if the vendor controls the data, defines outages narrowly, or can excuse repeated failures through loose carveouts.
For modern startups, the checklist also needs to cover risks older SLA templates ignore. If the service handles customer data, model inputs, internal analytics, or AI-enabled features, implementation should confirm who reviews vendor notices, who monitors service credits, and who flags changes in data use or subprocessors before those changes create legal or product risk.
Post-signature checklist
Signing starts the actual work.
- Assign an owner: Name one person to review reports, track misses, receive vendor notices, and coordinate legal, security, and operations when performance slips.
- Map the covered services: Document which products, integrations, internal teams, and customer commitments depend on the vendor so an SLA miss can be tied to business impact quickly.
- Archive the evidence: Store reports, support tickets, incident summaries, change notices, and escalation correspondence in one system. If you need credits, a termination right, or a contract claim later, scattered records make enforcement harder.
- Test the measurement method: Confirm your team can verify uptime, response times, queue times, or other metrics against actual system behavior instead of relying only on the vendor dashboard.
- Review exclusions early: Push back on vague maintenance windows, force majeure language used for ordinary failures, and third-party dependency carveouts that swallow the promise.
- Track repeat issues: One missed metric may be tolerable. A pattern of smaller misses often matters more because it shows a service that is degrading without triggering a dramatic breach.
- Confirm escalation paths: Make sure named contacts, response times, and decision-makers are still current. An escalation clause fails fast if the contact list is stale.
- Calendar periodic review: Revisit the SLA when scope changes, new integrations are added, customer commitments tighten, or the vendor starts using data in new ways.
This discipline turns the SLA from procurement paperwork into an operating control. Startups that treat it that way are in a better position to claim credits, force action, or exit a vendor relationship before a service problem becomes a customer retention problem.
A strong service level agreement template reduces ambiguity before a failure. For a startup, that means clearer accountability, faster escalation, and fewer arguments over what the vendor promised. Founders who need legal help drafting, reviewing, or negotiating an SLA alongside contract, privacy, cybersecurity, or AI risk issues can work with By Design Law Firm & Legal Consultancy, PLLC for practical guidance built for technology-driven businesses. Call us at (206) 593-1519.


